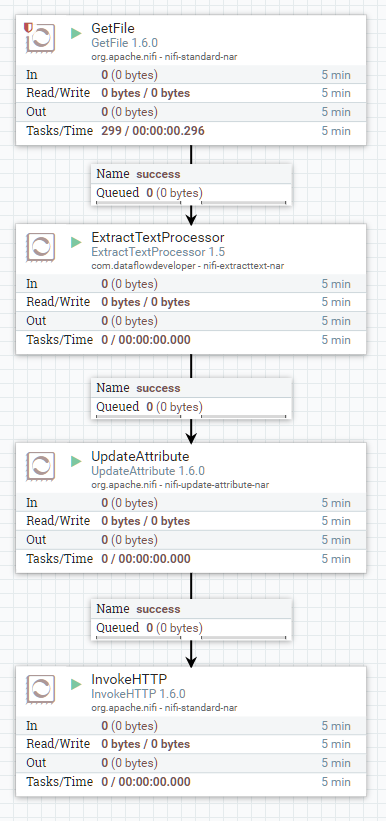
2-6 Extract Text from PDFs and Office Documents
This example uses the ExtractTextProcessor which is not included with NiFi but was developed by Hortonworks. ExtractTextProcessor uses Apache Tika to extract the text from a wide variety of document formats.
The output from the processor can be html (XHTML) or text. I recommend the html option because it also converts the text to UTF-8. In my testing the text option produced output in a mix of character sets, UTF-8 and Windows-1252, the latter failing on ingest.
For the purposes of this test I downloaded the pre-built NAR file from here. Drop the NAR file into the NiFi lib directory and restart. All dependencies, including Tika, are included in the NAR.
- ExtractTextProcessor GitHub project
- ExtractText NiFi Custom Processor Powered by Apache Tika (Hortonworks Community)
- Download Template
- Processors:
- GetFile – reads files from a watched directory
- Properties
- Input Directory: /some/path
- Properties
- ExtractTextProcessor
- Properties
- HTML Output instead of text: html
- Properties
- UpdateAttribute
- Properties
- marklogic.uri: /${filename:replaceAll(" ", "_")}/${filename:replaceAll(" ", "_")}.html
- Properties
- InvokeHTTP – HTTP PUT to MarkLogic REST API /LATEST/documents
- Properties
- HTTP Method: PUT
- Remote URL: http://localhost:8000/LATEST/documents?uri=${marklogic.uri}
- Basic Authentication Username: youruser
- Basic Authentication Password: yourpassword
- Settings
- Check all five checkboxes under "Automatically Terminate Relationships"
- Properties
- GetFile – reads files from a watched directory